写在前面
这是可以说的吗🫣🫣🫣
Efficient Training
调超参的时候可以先试试用Imagenet的100类试试,调的差不多了再上全部。
SNN Transformer Training
Transformer的常用Base lr是1e-4,adamw下是1e-4到6e-4之间,lamb可能需要再精调。adamw的前期收敛性太强了建议学习率linear warmup,用log怕炸
C-Optim
stdconv -> adaptive_clip clip_grad=0.02
正常的linear就torch自带的clip clip_grad=1 or 5
FasterViT?
Spike-driven Transformer V2/V3
检测与分割:除了backbone都是整数不norm
卷积算子貌似和整数(不带norm)很适配、attention貌似很和小数(带norm)适配
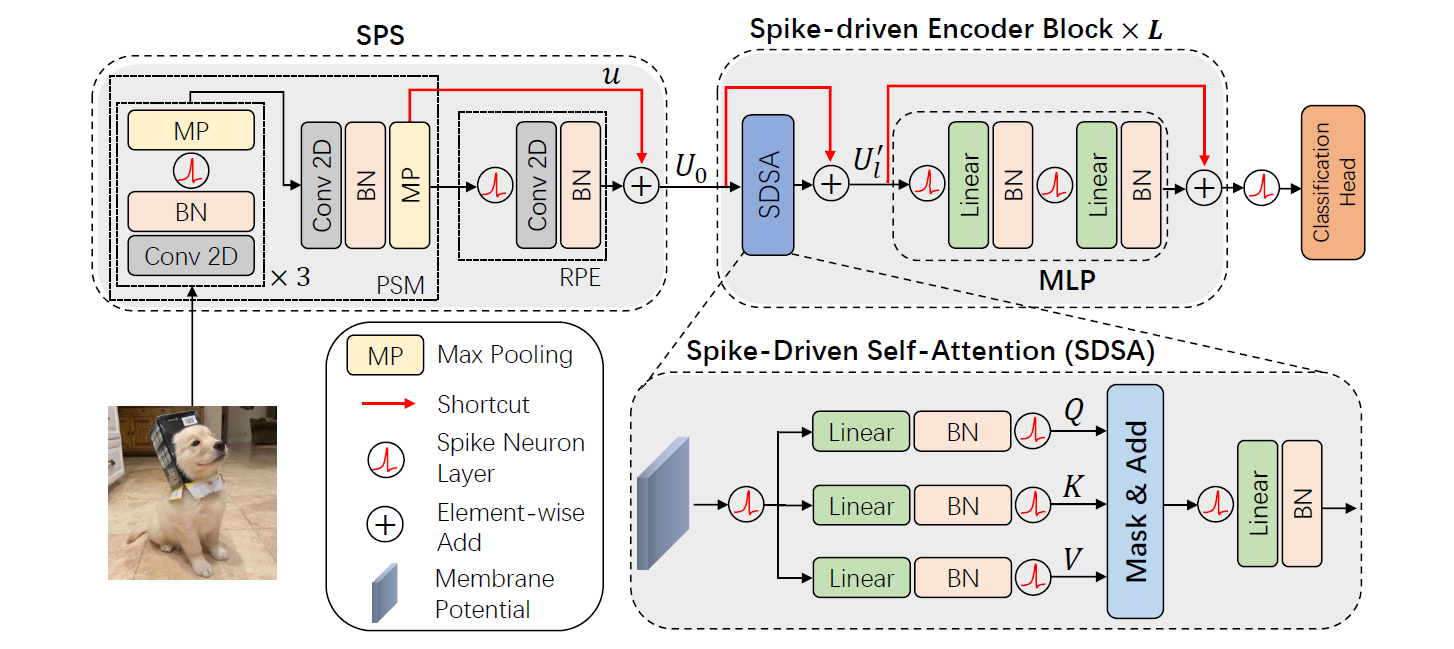
Spike-driven Transformer V1
About Finetuning SDT-V1 (Contributed by Qian S., 2025-04-28)
v1没有提供微调的代码,微调的方法:.yml文件不需要改 (可能需要改一个epochs)
main.py找到create_model:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| model = create_model(
args.model,
T=args.time_steps,
pretrained=args.pretrained,
drop_rate=args.drop,
drop_path_rate=args.drop_path,
drop_block_rate=args.drop_block,
num_heads=args.num_heads,
num_classes=args.num_classes,
pooling_stat=args.pooling_stat,
img_size_h=args.img_size,
img_size_w=args.img_size,
patch_size=args.patch_size,
embed_dims=args.dim,
mlp_ratios=args.mlp_ratio,
in_channels=args.in_channels,
qkv_bias=False,
depths=args.layer,
sr_ratios=1,
spike_mode=args.spike_mode,
dvs_mode=args.dvs_mode,
TET=args.TET,
)
|
把args.pretrained注释掉,加下面两行代码:
1
2
| pretrained=True,
checkpoint_path=your/path,
|
改后代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| model = create_model(
args.model,
T=args.time_steps,
pretrained=True,
checkpoint_path='/data/users/sunq/S-Transformer/weights/cifar100_4_384.pth.tar',
drop_rate=args.drop,
drop_path_rate=args.drop_path,
drop_block_rate=args.drop_block,
num_heads=args.num_heads,
num_classes=args.num_classes,
pooling_stat=args.pooling_stat,
img_size_h=args.img_size,
img_size_w=args.img_size,
patch_size=args.patch_size,
embed_dims=args.dim,
mlp_ratios=args.mlp_ratio,
in_channels=args.in_channels,
qkv_bias=False,
depths=args.layer,
sr_ratios=1,
spike_mode=args.spike_mode,
dvs_mode=args.dvs_mode,
TET=args.TET,
)
|
(Updated by Qian S., 2025-06-04)
当引入了新的可学习参数时,这种方法就不适用了,因为这个函数的默认strict=True。因此,可以这样做:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| model = create_model(
args.model,
T=args.time_steps,
pretrained=False,
drop_rate=args.drop,
drop_path_rate=args.drop_path,
drop_block_rate=args.drop_block,
num_heads=args.num_heads,
num_classes=args.num_classes,
pooling_stat=args.pooling_stat,
img_size_h=args.img_size,
img_size_w=args.img_size,
patch_size=args.patch_size,
embed_dims=args.dim,
mlp_ratios=args.mlp_ratio,
in_channels=args.in_channels,
qkv_bias=False,
depths=args.layer,
sr_ratios=1,
spike_mode=args.spike_mode,
dvs_mode=args.dvs_mode,
TET=args.TET,
)
load_checkpoint(model, '/data/users/sunq/S-Transformer/weights/cifar10_4_384.pth.tar', strict=False)
|
把checkpoint移下来,新加一行,在load_checkpoint()里面把strict设置为False即可。

 wechat
wechat