Status: 施工中🏗️
0. Contents
Titans: Learning to Memorize at Test Time
1. Titans: 测试时记忆
Abstract
摘要部分提到:
We present a new neural long-term memory module that learns to memorize historical context and helps an attention to attend to the current context while utilizing long past information, …, has the advantage of a fast parallelizable training while maintaining a fast inference.
Titans提出的长程记忆模块解决Attention在做注意力计算时捕捉不到很早期的历史信息(scale to larger than 2M context window size)。从记忆形成的视角,作者认为Attention扮演着短期记忆的功能:上下文短但能精确建模依赖关系;而Titans的记忆模块扮演着长程记忆的功能:能够记住很长时间之前的信息。
Intro
Attention曾在NeurIPS24的一篇文章:Birth of a Transformer: A Memory Viewpoint 中认为起到associative memory(联想记忆)的功能。因为Attention捕获的K-V关系,在输入(Q)到来时与K对比,从而得到有效输出。
具体内容这篇文章zb还没有看,mark一下以后有时间看看
Modern Methods in Associative Memory ICML 2025 Tutorial
Birth of a Transformer: A Memory Viewpoint, NeurIPS 2024
联想记忆(AM)貌似是一个比较老的研究热点,但是又和在线学习、Hebb规则、Hopfield网络有一定联系,这篇博客 中总结了很多关于AM的相关内容。
接上段,正是因为Attention的KV匹配机制,每一次得到的输出很明显是和当前的输入ctx窗内的内容有关系。它的时间和空间复杂度都是相对于ctx length是二次的,因此无法做ctx len极长的任务。
一些线性注意力模型的诞生,能够将内存使用压缩到线性,但是一个极长的ctx的信息无法被有效压缩成一个matrix-valued states。
抛开高效性,从远古的Hopfield网络,到LSTM、Transformer,模型的泛化性、长度外延、(复杂)推理能力都是真实场景中复杂任务需要的。一些从所谓“脑启发”得到的idea需要再被审视:
学习过程中,将以往信息注入到当前输入的关键模块
这些组件如何构成可独立运行的互连系统
能够主动从数据中学习并记住过去历史的抽象概念
Memory Perspective
在生物学里,记忆关乎基本的反射和刻板行为形成。大多数现有神经网络架构将记忆视为由输入引起的神经更新(Neural Update,我真不知道怎么翻译…) ,并将学习定义为:在给定目标的情况下,获取有效且有用记忆的过程。 。我们能得到以下的表格:
模型
记忆模块
记忆的更新方式
检索记忆的方式(输出)
RNN
向量表示的记忆模块 (vector-valued memory module)M ∈ R n \mathcal{M} \in \mathbb{R}^{n} M ∈ R n 输入x t x_t x t F ( x t , M t − 1 ) \mathcal{F}(x_{t}, \mathcal{M}_{t-1}) F ( x t , M t − 1 )
G ( x t , M t ) \mathcal{G}(x_{t}, \mathcal{M}_{t}) G ( x t , M t )
Transformer
K、V矩阵表示的记忆模块 K , V ∈ R T × d K,V \in \mathbb{R}^{T \times d} K , V ∈ R T × d 输入x t x_t x t ( K t , V t ) = f ( x t ) (K_t,V_t)=f(x_t) ( K t , V t ) = f ( x t ) KV t = KV t − 1 ∪ ( K t , V t ) \text{KV}_t=\text{KV}_{t-1}\cup(K_t,V_t) KV t = KV t − 1 ∪ ( K t , V t )
基于 Query 的注意力检索:Attn ( Q t , K 1 : t , V 1 : t ) \text{Attn}(Q_t, K_{1:t}, V_{1:t}) Attn ( Q t , K 1 : t , V 1 : t )
Linear Attention
矩阵表示的记忆模块 (matrix-valued memory module)M t ∈ R d k × d v \mathcal{M}_t \in \mathbb{R}^{d_k \times d_v} M t ∈ R d k × d v 特征映射后做外积累积(压缩/汇总): ϕ ( K t ) = ϕ ( f K ( x t ) ) , V t = f V ( x t ) \;\phi(K_t)=\phi(f_K(x_t)),\; V_t=f_V(x_t) ϕ ( K t ) = ϕ ( f K ( x t )) , V t = f V ( x t ) M t = M t − 1 + ϕ ( K t ) V t ⊤ \;\mathcal{M}_t=\mathcal{M}_{t-1}+\phi(K_t)V_t^\top M t = M t − 1 + ϕ ( K t ) V t ⊤
线性读出(内容寻址):Q t = f Q ( x t ) Q_t=f_Q(x_t) Q t = f Q ( x t ) out t = ϕ ( Q t ) ⊤ M t \;\text{out}_t=\phi(Q_t)^\top \mathcal{M}_t out t = ϕ ( Q t ) ⊤ M t
Transformer和Linear Attention的本质区别在于,前者的记忆模块.是.append()的,会不断增大的,;而者是通过运算压缩成一个固定长度的matrix。
但记忆不是一个单一的功能模块,而是由好多个模块构成的复杂系统(短期记忆、工作记忆、长期记忆…(至少已现在人类对于记忆机制的探索是这些))。
Titans文章的贡献:
基于人类长期记忆提出了一个Test-time memory module(测试时记忆模块),能够对expectations产生violation的/感到surprised的输入记得更牢(more memorable),这个过程依赖于associative memory loss(关联记忆损失函数)来衡量surprise程度,本质是神经网络对输入的梯度 。
鉴于记忆容量的有限性,施加衰减机制(decay mechanism)用于考虑现有data surprise和propotion of the memory size。其本质也和很多网络中的forgetting gate 没有区别。这种机制等价于优化一个具有小批量梯度下降、动量和权重衰减的元神经网络。
为了高效快速训练这个记忆模块,提出了一种依赖增加矩阵运算 的训练算法,灵感来源于原始的TTT (埋坑ing…)
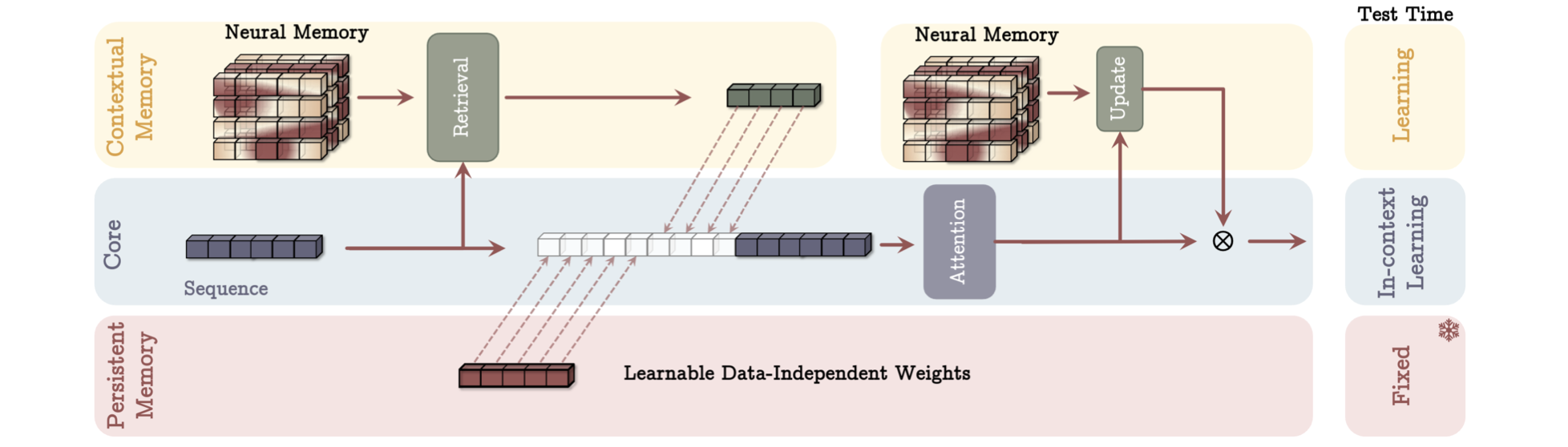
提出Titans系列的模型架构,将上面的记忆模块整合进现有模型: 包含three hyper-heads):
hyper-heads为什么要叫这个名字我也不知道…
组件
实现方式
Core(核心)/Short-term memory(短期记忆模块)
attention with limited window size(带窗口的注意力),是主要的数据流动的组件
Long-term Memory(长期记忆模块)
储存和记忆很长时间之前的东西
Persistent Memory(永久记忆)
a set of learnable but date-independent parameters (一组可学习但是输入依赖的参数)
三种Titans的变体: 把记忆整合成:
(i) a context【上下文】,
(ii) a layer 【层】,
(iii) a gated branch 【门控分枝】.
实验:包括language modeling, commonsense reasoning, recall-intensive, needle in haystack, time series forecasting, and DNA modeling tasks
Preliminaries
Notations
Notation
Descr.
x ∈ R n × d i n x \in \mathbb{R}^{n \times d_{in}} x ∈ R n × d in 模型接受的输入
M \mathcal{M} M 神经网络模块/记忆模块
Q , K , V Q,K,V Q , K , V 自注意力机制的查询(query)、键(key)、值(value)
M M M 自注意力的attention mask(掩码)
S ( i ) S^{(i)} S ( i ) 将一个序列分段的第i i i
S j ( i ) S^{(i)}_{j} S j ( i ) 第i i i j j j
N ( x ) \mathcal{N}(x) N ( x ) 输入x x x N \mathcal{N} N 带权重修正(with weight adjustment) 的前向传播
N ∗ ( x ) \mathcal{N}^*(x) N ∗ ( x ) 输入x x x N \mathcal{N} N 不带权重修正(without weight adjustment) 的前向传播
N ( j ) \mathcal{N}^{(j)} N ( j ) 神经网络N \mathcal{N} N j j j
给定输入$x \in \mathbb{R}^{n \times d_{in}}, $ 其中 n n n d i n d_{in} d in y ∈ R n × d i n y \in \mathbb{R}^{n \times d_{in}} y ∈ R n × d in
Q = x W Q , K = x W k , V = x W v . ( W □ ∈ R d i n × d i n ) Q=xW_Q, \space K=xW_k, \space V=xW_v.\quad(W_{\square} \in \mathbb{R^{d_{in} \times d_{in}}})
Q = x W Q , K = x W k , V = x W v . ( W □ ∈ R d in × d in )
y i = ∑ j = 1 i exp ( Q i ⊤ K j d i n ) V j ∑ ℓ = 1 j exp ( Q i ⊤ K ℓ d i n ) y_i = \sum_{j=1}^{i} \frac{\exp(\frac{Q_i^\top K_j}{\sqrt{d_{in}}})V_j}{\sum_{\ell=1}^{j}\exp(\frac{Q_i^\top K_\ell}{\sqrt{d_{in}}})}
y i = j = 1 ∑ i ∑ ℓ = 1 j exp ( d in Q i ⊤ K ℓ ) exp ( d in Q i ⊤ K j ) V j
高效自注意力的策略:
1. 注意力矩阵稀疏化
2. Softmax() \text{Softmax()} Softmax()
3. Kernel-based (linear) attentions
Kernel function ϕ ( ⋅ ) \phi(\cdot) ϕ ( ⋅ )
ϕ ( x , y ) = ϕ ( x ) ϕ ( y ) \phi(x,y)=\phi(x)\phi(y)
ϕ ( x , y ) = ϕ ( x ) ϕ ( y )
自注意力可以改写为:
y i = ∑ j = 1 i ϕ ( Q i , K j ) V j ∑ ℓ = 1 i ϕ ( Q i , K ℓ ) = ∑ j = 1 i ϕ ( Q i ) ⊤ ϕ ( K j ) V j ∑ ℓ = 1 i ϕ ( Q i ) ⊤ ϕ ( K ℓ ) = ϕ ( Q i ) ⊤ ∑ j = 1 i ϕ ( K j ) V j ϕ ( Q i ) ⊤ ∑ ℓ = 1 i ϕ ( K ℓ ) y_i = \sum_{j=1}^{i}\frac{\phi(Q_i,K_j)V_j}{\sum_{\ell=1}^{i}\phi(Q_i,K_\ell)}=\sum_{j=1}^{i}\frac{\phi(Q_i)^\top\phi(K_j)V_j}{\sum_{\ell=1}^{i}\phi(Q_i)^\top\phi(K_\ell)}=\frac{\phi(Q_i)^\top\sum_{j=1}^{i}\phi(K_j)V_j}{\phi(Q_i)^\top\sum_{\ell=1}^{i}\phi(K_\ell)}
y i = j = 1 ∑ i ∑ ℓ = 1 i ϕ ( Q i , K ℓ ) ϕ ( Q i , K j ) V j = j = 1 ∑ i ∑ ℓ = 1 i ϕ ( Q i ) ⊤ ϕ ( K ℓ ) ϕ ( Q i ) ⊤ ϕ ( K j ) V j = ϕ ( Q i ) ⊤ ∑ ℓ = 1 i ϕ ( K ℓ ) ϕ ( Q i ) ⊤ ∑ j = 1 i ϕ ( K j ) V j
上式中,项∑ j = 1 i ϕ ( K j ) \sum_{j=1}^{i}\phi(K_j) ∑ j = 1 i ϕ ( K j ) ∑ ℓ = 1 i ϕ ( K ℓ ) \sum_{\ell=1}^{i}\phi(K_\ell) ∑ ℓ = 1 i ϕ ( K ℓ )
当ϕ ( ⋅ ) \phi(\cdot) ϕ ( ⋅ ) ϕ ( x ) = x \phi(x)=x ϕ ( x ) = x
y i = Q i ⊤ ∑ j = 1 i K j ⊤ V j Q i ⊤ ∑ ℓ = 1 i K ℓ y_i = \frac{Q_i^\top\sum_{j=1}^{i}K_j^\top V_j}{Q_i^\top\sum_{\ell=1}^{i}K_\ell}
y i = Q i ⊤ ∑ ℓ = 1 i K ℓ Q i ⊤ ∑ j = 1 i K j ⊤ V j
令M t = ∑ j = 1 t K t ⊤ V t \mathcal{M}_t=\sum_{j=1}^{t}K_t^\top V_t M t = ∑ j = 1 t K t ⊤ V t
M t = M t − 1 + K t ⊤ V t \mathcal{M}_t=\mathcal{M}_{t-1} + K_t^\top V_t
M t = M t − 1 + K t ⊤ V t
y t = Q t M t Q i ⊤ ∑ ℓ = 1 i K ℓ y_t = \frac{Q_t\mathcal{M}_t}{Q_i^\top \sum_{\ell=1}^{i}K_\ell^{}}
y t = Q i ⊤ ∑ ℓ = 1 i K ℓ Q t M t
现代循环模型以及与记忆系统的关联
如果把RNN中的hidden states当成网络的“记忆储存”,那么这个记忆系统的读和写过程就是:
M t = f ( M t − 1 , x t ) , (writing process) \mathcal{M}_t = f(\mathcal{M}_{t-1}, x_t), \text{(writing process)}
M t = f ( M t − 1 , x t ) , (writing process)
y t = g ( M t , x t ) , (reading process) y_t = g(\mathcal{M}_{t}, x_t), \text{(reading process)}
y t = g ( M t , x t ) , (reading process)
直观上来看,linear attention单纯将记忆更新的过程建模成一个纯加性的,势必会导致记忆溢出(memory overflow) 。因此,后来的研究集中在记忆更新时 f ( ⋅ ) f(\cdot) f ( ⋅ ) g ( ⋅ ) g(\cdot) g ( ⋅ )
添加遗忘机制(forgetting mechanism):GLA、LRU、Griffin、xLSTM、Mamba2
Delta Rule:在添加记忆(即键值对)之前,模型首先会删除其过去的值。并对这个过程加入chunkwise的高效训练。
记忆模型
将线性层视为键值(关联)记忆(Key-value associative memory)系统的想法可以追溯到快速权重程序(fast weight programs),其中动态快速程序(dynamic fast
FWP和Linear attention的形式真的是一模一样…
Fast weights的训练形式也有两种基本的学习规则来主导:Hebbian Rule和Delta Rule。
Hebbian Rule:“一起激发的神经元,会建立更强的连接(Cells that fire together, wire together)。”
但是,上面的所有研究忽略了两个重要的问题:tokens在网络中的传播过程 以及 大多都缺乏遗忘门
❓原文:“most of them lacks a forgetting gate, resulting in a poor memory management.”
Methods:
长期记忆模块的设计
原理
LLM 已被证明能够记住其训练数据,受此启发,我们只需要训练一个神经网络去做这种事情不就好了 。但记忆本身的泛化性、隐私问题导致的Test-time表现很差。并且,记住训练数据对于test-time任务提升并不突出。因此,我们需要一个在线元模型(online meta-model) ,该模型能够学习如何在测试时记忆/遗忘数据 。还要要求能够记忆数据的同时,不会过度拟合。
转化为一个online learning problem(在线学习的问题)
一个令“神经网络 M \mathcal{M} M 网络相对于输入的梯度 来量度这一意外的程度,训练一个神经网络用于压缩前面所有时刻的输入 x 1 , . . . , x t x_1, ..., x_t x 1 , ... , x t
M t = M t − 1 − θ t ∇ ℓ ( M t − 1 ; x t ) ⏟ Surprise M_t = M_{t-1} - \theta_t \, \underbrace{\nabla_ \ell\!\left(M_{t-1}; x_t\right)}_{\text{Surprise}}
M t = M t − 1 − θ t Surprise ∇ ℓ ( M t − 1 ; x t )
随之而来的问题是,当一个有记忆价值的moment到来,假如很大,相当于一步学习的步子迈得很大,于是存在容易陷入局部最优(local minima)的可能。从人类记忆的角度而言,一个被认为有记忆价值的瞬间,过了一阵子可能就不那么令人意外了。也就是说,时间长了之后,这个Surprise也就不够surprise了。于是我们将上式拆成以下形式:
M t = M t − 1 + S t , S t = η t S t − 1 ⏟ Past Surprise − θ t ∇ ℓ ( M t − 1 ; x t ) ⏟ Momentary Surprise . \begin{aligned}
M_t &= M_{t-1} + S_t, \\
S_t &= \eta_t \, \underbrace{S_{t-1}}_{\text{Past Surprise}}
\;-\; \theta_t \, \underbrace{\nabla_\ell\!\left(M_{t-1}; x_t\right)}_{\text{Momentary Surprise}} .
\end{aligned}
M t S t = M t − 1 + S t , = η t Past Surprise S t − 1 − θ t Momentary Surprise ∇ ℓ ( M t − 1 ; x t ) .
有趣的是,这种公式类似于带动量的梯度下降法,其中 S t S_t S t
动量梯度下降法(Momentum Gradient Descent) 的标准数学形式:
v t = μ v t − 1 − η ∇ f ( θ t − 1 ) θ t = θ t − 1 + v t \begin{aligned}
v_t &= \mu v_{t-1} - \eta \nabla f(\theta_{t-1}) \\
\theta_t &= \theta_{t-1} + v_t
\end{aligned} v t θ t = μ v t − 1 − η ∇ f ( θ t − 1 ) = θ t − 1 + v t
其中,θ t \theta_t θ t v t v_t v t μ \mu μ η \eta η Nesterov 动量 :梯度在θ t − 1 + μ v t − 1 \theta_{t-1} + \mu v_{t-1} θ t − 1 + μ v t − 1 θ t − 1 \theta_{t-1} θ t − 1
v t = μ v t − 1 − η ∇ f ( θ t − 1 + μ v t − 1 ) v_t = \mu v_{t-1} - \eta \nabla f(\theta_{t-1}+\mu v_{t-1})
v t = μ v t − 1 − η ∇ f ( θ t − 1 + μ v t − 1 )
这预见了运动,尤其是在病态问题中,可能提供更准确的梯度方向信息。
至于到底能否解决提到的过度surprise的问题:
∏ n j ≤ 1 → old surprise → 0 \prod n_j \leq 1 \rightarrow \text{old surprise} \rightarrow 0 ∏ n j ≤ 1 → old surprise → 0
与动量梯度下降不同的是,记忆更新公式中的 η t \eta_t η t x t x_t x t θ t \theta_t θ t
虽然前一个标记的意外性可能会影响下一个标记的意外性,但只有当所有标记都相关且处于同一上下文中时,这种依赖性才基本有效。
记忆模块是一个元模型(meta model),它基于损失函数 ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ ( ⋅ , ⋅ )
ℓ ( M t − 1 ; x t ) = ∥ M t − 1 ( k t ) − v t ∥ 2 2 . \ell(\mathcal{M}_{t-1}; x_t) = \left\| \mathcal{M}_{t-1}(\mathbf{k}_t) - \mathbf{v}_t \right\|_2^2 .
ℓ ( M t − 1 ; x t ) = ∥ M t − 1 ( k t ) − v t ∥ 2 2 .
跟RWKV-v7一模一样…
类似于元学习模型,记忆的训练发生在内循环中,因此参数 W K W_K W K W V W_V W V 超参数(hyperparameters) 。在内循环中我们优化的是 M \mathcal{M} M
即便对于很大容量的记忆空间,一个记忆系统也要学会怎么遗忘 。所以,进一步改进上面的记忆更新公式,加入遗忘机制 :
M t = ( 1 − α t ) M t − 1 + S t ( α t ∈ [ 0 , 1 ] ) , S t = η t S t − 1 − θ t ∇ ℓ ( M t − 1 ; x t ) . \begin{aligned}
M_t &= \red{(1-\alpha_t)}M_{t-1} + S_t \quad (\alpha_t \in [0,1]),\\
S_t &= \eta_t S_{t-1}
-\theta_t \nabla_\ell\left(M_{t-1}; x_t\right).
\end{aligned}
M t S t = ( 1 − α t ) M t − 1 + S t ( α t ∈ [ 0 , 1 ]) , = η t S t − 1 − θ t ∇ ℓ ( M t − 1 ; x t ) .
架构设计
Titans为了验证基本的理论构想,使用了较为简单的大于等于1层的MLP 做长期记忆模块。
当使用向量值或矩阵值记忆时,记忆模块会压缩历史数据并将其拟合成一条直线。
从元学习或在线学习的角度来看, M \mathcal{M} M R d i n × d i n \mathbb{R}^{d_{in} \times d_{in}} R d in × d in
ℓ ( W t − 1 ; x t ) = ∥ W t − 1 k t − v t ∥ 2 2 . \ell(W_{t-1}; x_t) = \left\| W_{t-1}\mathbf{k}_t - \mathbf{v}_t \right\|_2^2 .
ℓ ( W t − 1 ; x t ) = ∥ W t − 1 k t − v t ∥ 2 2 .
最优解假设历史数据的潜在依赖关系是线性的。
从记忆中检索
使用前向传播(不更新权重,即推理)来检索与查询对应的记忆。
训练优化
利用小批量梯度下降、数据相关的学习率和权重衰减来计算内循环中的权重,可以重新表述为 仅使用矩阵乘法matmul和求和(sum) 的过程。
split the sequence into chunks of size b ≥ 1 b \geq 1 b ≥ 1
记忆更新过程展开可以重写为
S t = η t S t − 1 − θ t ∇ ℓ ( M t − 1 ; x t ) = η t ( η t − 1 S t − 2 − θ t − 1 ∇ ℓ ( M t − 2 ; x t − 1 ) ) − θ t ∇ ℓ ( M t − 1 ; x t ) = η t ( η t − 1 S t − 2 − θ t − 1 g t − 1 ) − θ t g t = η t η t − 1 S t − 2 − η t θ t − 1 g t − 1 − θ t g t = … = ∏ j = 1 t η j S 0 − ∑ i = 1 t θ i ( ∏ ℓ = i + 1 t η ℓ ) g i M t = ∏ j = 1 t ( 1 − α j ) M 0 + ∑ k = 1 t S k = ∏ j = 1 t ( 1 − α j ) M 0 + ∑ k = 1 t [ ∏ j = 1 k η j S 0 − ∑ i = 1 k θ i ( ∏ ℓ = i + 1 k η ℓ ) g i ] = ∏ j = 1 t ( 1 − α j ) M 0 + S 0 ∑ k = 1 t [ ∏ j = 1 k η j ] − ∑ i = 1 k θ i [ ∑ k = 1 t ( ∏ ℓ = i + 1 k η ℓ ) ] g i \begin{aligned}
S_t&=\eta_t S_{t-1}-\theta_t \nabla_\ell\left(M_{t-1}; x_t\right) \\
&=\eta_t (\eta_{t-1} S_{t-2}-\theta_{t-1} \nabla_\ell\left(M_{t-2}; x_{t-1}\right))-\theta_t \nabla_\ell\left(M_{t-1}; x_t\right) \\
&= \eta_t (\eta_{t-1} S_{t-2}-\theta_{t-1} g_{t-1})-\theta_t g_{t} \\
&= \eta_t \eta_{t-1} S_{t-2}- \eta_t \theta_{t-1} g_{t-1}-\theta_t g_{t} \\
&= \dots \\
&= \prod_{j=1}^{t}\eta_j S_0 - \sum_{i=1}^{t} \theta_i (\prod_{\ell=i+1}^{t} \eta_{\ell}) g_i \\
M_t&=\prod_{j=1}^{t}(1-\alpha_j)M_0+\sum_{k=1}^{t}S_k \\
&=\prod_{j=1}^{t}(1-\alpha_j)M_0+\sum_{k=1}^{t}[\prod_{j=1}^{k}\eta_j S_0 - \sum_{i=1}^{k} \theta_i (\prod_{\ell=i+1}^{k} \eta_{\ell}) g_i] \\
&=\prod_{j=1}^{t}(1-\alpha_j)M_0+ S_0 \sum_{k=1}^{t} [\prod_{j=1}^{k}\eta_j] - \sum_{i=1}^{k} \theta_i [\sum_{k=1}^{t} (\prod_{\ell=i+1}^{k} \eta_{\ell})] g_i
\end{aligned} S t M t = η t S t − 1 − θ t ∇ ℓ ( M t − 1 ; x t ) = η t ( η t − 1 S t − 2 − θ t − 1 ∇ ℓ ( M t − 2 ; x t − 1 ) ) − θ t ∇ ℓ ( M t − 1 ; x t ) = η t ( η t − 1 S t − 2 − θ t − 1 g t − 1 ) − θ t g t = η t η t − 1 S t − 2 − η t θ t − 1 g t − 1 − θ t g t = … = j = 1 ∏ t η j S 0 − i = 1 ∑ t θ i ( ℓ = i + 1 ∏ t η ℓ ) g i = j = 1 ∏ t ( 1 − α j ) M 0 + k = 1 ∑ t S k = j = 1 ∏ t ( 1 − α j ) M 0 + k = 1 ∑ t [ j = 1 ∏ k η j S 0 − i = 1 ∑ k θ i ( ℓ = i + 1 ∏ k η ℓ ) g i ] = j = 1 ∏ t ( 1 − α j ) M 0 + S 0 k = 1 ∑ t [ j = 1 ∏ k η j ] − i = 1 ∑ k θ i [ k = 1 ∑ t ( ℓ = i + 1 ∏ k η ℓ )] g i
令 β t = ∏ j = 1 t ( 1 − α j ) \beta_t = \prod_{j=1}^{t}(1-\alpha_j) β t = ∏ j = 1 t ( 1 − α j ) M t = β t M 0 + S 0 ∑ k = 1 t [ ∏ j = 1 k η j ] − ∑ i = 1 k θ i [ ∑ k = 1 t ( ∏ ℓ = i + 1 k η ℓ ) ] g i M_t = \beta_t M_0+ S_0 \sum_{k=1}^{t} [\prod_{j=1}^{k}\eta_j] - \sum_{i=1}^{k} \theta_i [\sum_{k=1}^{t} (\prod_{\ell=i+1}^{k} \eta_{\ell})] g_i M t = β t M 0 + S 0 ∑ k = 1 t [ ∏ j = 1 k η j ] − ∑ i = 1 k θ i [ ∑ k = 1 t ( ∏ ℓ = i + 1 k η ℓ )] g i
原文中其实隐含了一个自定的假设:论文里 η 和 (1−α) 不是两个独立的东西,inner-loop reformulation 里,实际上 ηₜ ≡ (1−αₜ)
原论文中表示为:
M t = β t M 0 − ∑ i = 1 t θ i β t β i g t ′ M_t = \beta_t M_0 - \sum_{i=1}^{t} \theta_i \frac{\beta_t}{\beta_i} g_{t'}
M t = β t M 0 − i = 1 ∑ t θ i β i β t g t ′
其中, t ′ = t − mod ( t , b ) t' = t - \text{mod}(t,b) t ′ = t − mod ( t , b )
在一个 chunk 内(长度为b),所有样本的梯度都用 chunk 起始时刻的参数来算,即 M t ′ , M t ′ + 1 , . . . , M t ′ + b − 1 M_{t'}, M_{t'+1} , ... , M_{t'+b-1} M t ′ , M t ′ + 1 , ... , M t ′ + b − 1 g t ′ , g t ′ + 1 , . . . , g t ′ + b − 1 g_{t'}, g_{t'+1}, ... , g_{t'+b-1} g t ′ , g t ′ + 1 , ... , g t ′ + b − 1 M t ′ M_{t'} M t ′ β t β i \frac{\beta_t}{\beta_i} β i β t
⚠️:不是代数恒等变形,而是模型重参数化(reparameterization)
论文在 inner loop reformulation 时,隐含做了下面这个假设:✅ Inner loop memory is zero-initialized.所以也就不考虑了 S 0 S_0 S 0
SGD 本来是一个“时间递归系统”。chunk = 把一段时间递归,压缩成一个“矩阵 × 向量 + 求和”的静态算子。
利用chunkwise简化梯度运算:
考虑第一个chunk,即 t = b , t ′ = 0 t = b, t'=0 t = b , t ′ = 0 M t = W t M_t = W_t M t = W t
∇ ℓ ( W 0 ; x t ) = ( W 0 x t − x t ) x t ⊤ \nabla_\ell(W_{0};x_t) = (W_0x_t - x_t)x_t^\top
∇ ℓ ( W 0 ; x t ) = ( W 0 x t − x t ) x t ⊤
∑ i = 1 t θ i β t β i g 0 = ∑ i = 1 b θ i β b β i ∇ ℓ ( W 0 ; x i ) = ∑ i = 1 b θ i β b β i ( W 0 x i − x i ) x i ⊤ = Θ b B b ( W 0 X − X ) X ⊤ \sum_{i=1}^{t} \theta_i \frac{\beta_t}{\beta_i} g_{0} = \sum_{i=1}^{b} \theta_i \frac{\beta_b}{\beta_i}\nabla_\ell(W_{0};x_i) = \sum_{i=1}^{b} \theta_i \frac{\beta_b}{\beta_i} (W_0x_i - x_i)x_i^\top = \Theta_b \Beta_b (W_0 X - X)X^\top
i = 1 ∑ t θ i β i β t g 0 = i = 1 ∑ b θ i β i β b ∇ ℓ ( W 0 ; x i ) = i = 1 ∑ b θ i β i β b ( W 0 x i − x i ) x i ⊤ = Θ b B b ( W 0 X − X ) X ⊤
其中,Θ b = diag ( [ θ 1 , θ 2 , . . . , θ b ] ) \Theta_b = \text{diag}([\theta_1, \theta_2, ..., \theta_b]) Θ b = diag ([ θ 1 , θ 2 , ... , θ b ]) B b \Beta_b B b β b β i \frac{\beta_b}{\beta_i} β i β b
对于所有的chunk,我们只需要存一次 Θ b , B b \Theta_b, \Beta_b Θ b , B b
S t S_t S t
S t = η t S t − 1 − θ t ∇ ℓ ( M t ′ ; x t ) S_t=\eta_t S_{t-1}-\theta_t \nabla_\ell\left(M_{t'}; x_t\right)
S t = η t S t − 1 − θ t ∇ ℓ ( M t ′ ; x t )
u t = ∇ ℓ ( M t ′ ; x t ) u_t = \nabla_\ell\left(M_{t'}; x_t\right) u t = ∇ ℓ ( M t ′ ; x t ) u t u_t u t S t S_t S t η t \eta_t η t parallel associative scan
Associative Scan(关联/结合扫描): 一种用在SSM的并行化计算策略。详细介绍参考这篇Blog . Associativity simply mean that we can apply the operator (denoted by ⋅ \cdot ⋅ cumsum()算子就是associative scan的例子。其实简单推一下就知道了: f ( x ) = a x + b , y = f 1 ( w ) = f 1 ( f 2 ( x ) ) f(x) = a x + b, y = f_1(w) = f_1(f_2(x)) f ( x ) = a x + b , y = f 1 ( w ) = f 1 ( f 2 ( x )) f 1 ⋅ f 2 = f 1 ( f 2 ( ⋅ ) ) = a ( c x + d ) + b = ( a c ) x + ( a d + b ) f_1 \cdot f_2 = f_1(f_2(\cdot)) = a(cx+d) + b = (ac)x + (ad+b) f 1 ⋅ f 2 = f 1 ( f 2 ( ⋅ )) = a ( c x + d ) + b = ( a c ) x + ( a d + b )
进一步:Parameter as chunk function
把 α t , η t , θ t \alpha_t, \eta_t, \theta_t α t , η t , θ t
但titans依然保留了token-wise的形式,没有采纳chunkwise的。
永久记忆(Persistent Memory)
如果说上面的long-term memory module是一种上下文记忆,那么persistent memory则是一种任务相关的记忆,换句话说是记住如何完成这项任务的知识。
在这一模块里,有 N p > 1 N_p \gt 1 N p > 1 [ p 1 , p 2 , . . . , p N p ] [p_1, p_2, ..., p_{N_p}] [ p 1 , p 2 , ... , p N p ] x x x N N N
x new = [ p 1 , p 2 , . . . , p N p ] ∣ ∣ x x_{\text{new}} = [p_1, p_2, ..., p_{N_p}] \space || \space x
x new = [ p 1 , p 2 , ... , p N p ] ∣∣ x
‘∣ ∣ || ∣∣
如何评价呢,有点像ViT need registers
带有因果掩码的注意力机制隐含地偏向序列中的初始标记(implicit bias),因此注意力权重几乎总是对初始标记高度活跃,导致性能下降 。从技术角度来看,序列开头的这些可学习参数可以通过更有效地重新分配注意力权重来缓解这种影响
记忆模块的整合
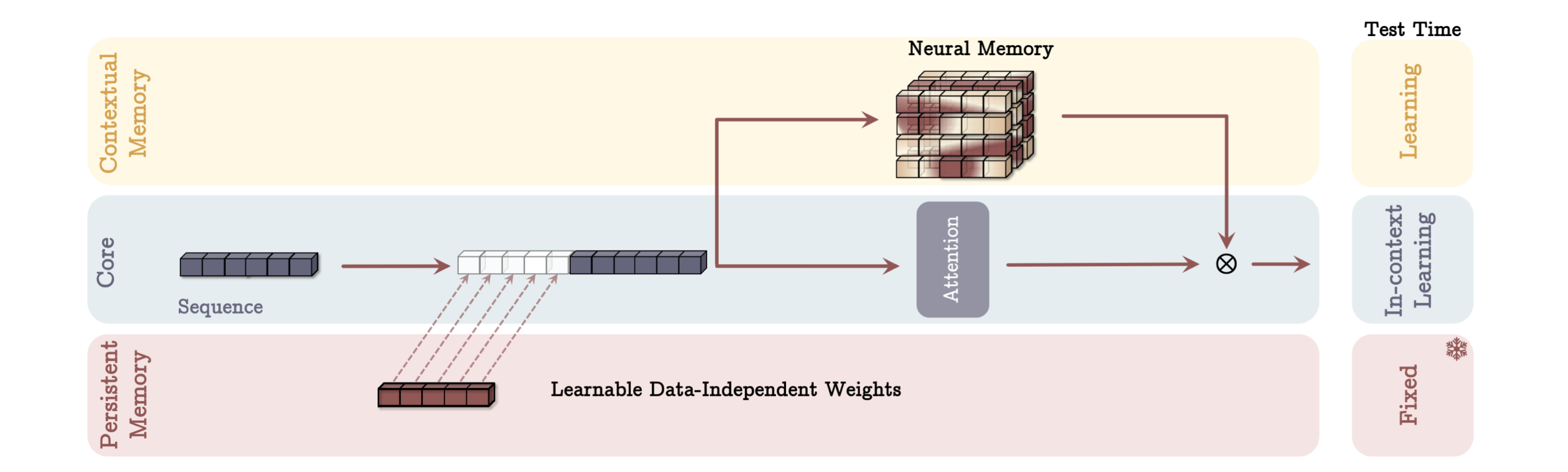
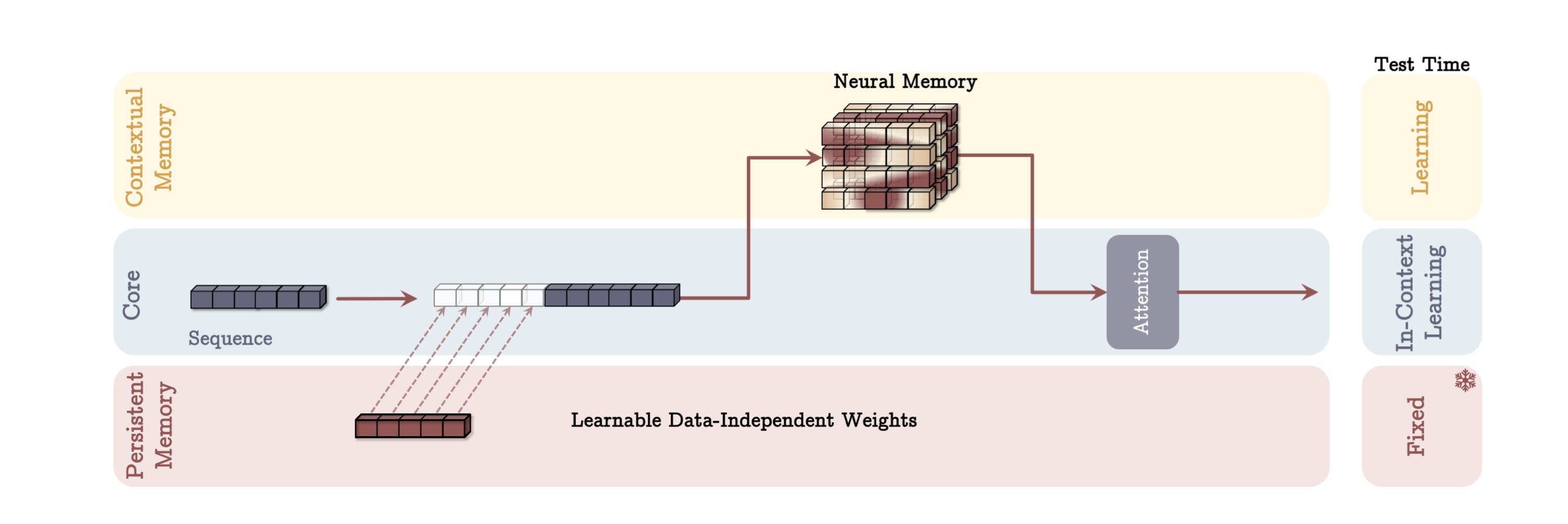
1. Memory as a Context (MAC)
给定一个输入序列 x ∈ R n × d i n x \in \mathbb{R}^{n \times d_{in}} x ∈ R n × d in S ( i ) , i = 1 , 2 , . . . , N / C S^{(i)}, i = 1, 2, ..., N / C S ( i ) , i = 1 , 2 , ... , N / C S ( t ) S^{(t)} S ( t ) S t − 1 , S t − 2 , . . . S^{t-1}, S^{t-2}, ... S t − 1 , S t − 2 , ... M t − 1 M_{t-1} M t − 1 S ( t ) S^{(t)} S ( t ) M t − 1 M_{t-1} M t − 1
h t = M t − 1 ∗ ( q t ) = M t − 1 ∗ ( W Q S ( t ) ) h_t = M_{t-1}^*(q_t) = M_{t-1}^*(W_Q S^{(t)})
h t = M t − 1 ∗ ( q t ) = M t − 1 ∗ ( W Q S ( t ) )
接下来,将这些历史信息以及Long-term memory参数作为注意力模块的输入序列:
S ( t ) ^ = [ p 1 , . . . , p N p ] ∣ ∣ h t ∣ ∣ S ( t ) \hat{S^{(t)}} = [p_1, ..., p_{Np}] || h_t || S^{(t)}
S ( t ) ^ = [ p 1 , ... , p Np ] ∣∣ h t ∣∣ S ( t )
y t = Attn ( S ( t ) ^ ) y_t = \text{Attn}(\hat{S^{(t)}})
y t = Attn ( S ( t ) ^ )
最后,用输出去更新Long-term Memory的状态:
M t = M t − 1 ( y t ) , o t = y t ⊗ M t ∗ ( y t ) M_t = M_{t-1}(y_t), o_t = y_t \otimes M_t^*(y_t)
M t = M t − 1 ( y t ) , o t = y t ⊗ M t ∗ ( y t )
Core分支里的attn如果还是传统的attention,复杂度还是O ( n 2 ) 啊。。。 O(n^2)啊。。。 O ( n 2 ) 啊。。。
2. Memory as a Gate
分两个分支:
第一个分支: 用输入 x x x 第二个分支: 用sliding window attention (SWA) with prefixx ^ = [ p 1 , . . . , p N p ] ∣ ∣ x y = SWA ( x ^ ) o = y ⊗ M ( x ^ ) \begin{aligned} \hat{x} &= [p_1, ..., p_{Np}] || x \\ y &= \text{SWA}(\hat{x}) \\ o &= y \otimes M(\hat{x}) \end{aligned}
x ^ y o = [ p 1 , ... , p Np ] ∣∣ x = SWA ( x ^ ) = y ⊗ M ( x ^ )
和第一种变体相比,Gated Memory的方式没有Chunk化。上式里的 ⊗ \otimes ⊗
这种方式在论文里没有显示地给出怎么更新 M M M
3. Memory as a Layer:
给定输入 x x x
x ^ = [ p 1 , . . . , p N p ] ∣ ∣ x y = M ( x ^ ) o = SWA ( y ) \begin{aligned} \hat{x} &= [p_1, ..., p_{Np}] || x \\ y &= M(\hat{x}) \\ o &= \text{SWA}(y) \end{aligned}
x ^ y o = [ p 1 , ... , p Np ] ∣∣ x = M ( x ^ ) = SWA ( y )
这种方式无法充分利用注意力机制和神经记忆模块的互补数据处理能力。
这种方式的一个变体是把long-term memory module当成一个不含注意力机制的模型,在论文的实验部分,这种变体称为(LMM/Titans)
迷惑。。。
Titans(LMM)应该是纯Linear RNN、而TItans(MAC/MAL/MAG)都是Hybrid Models.

 wechat
wechat