Linux Advanced Programming (Linux环境高级编程)
写在前面
任课教师:刘杰彦
参考教材:?
评分标准:NaN
知识点总结
习题
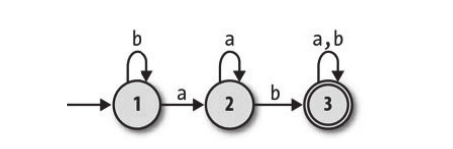
Finite Automaton Theory(有限自动机理论)
写在前面
任课教师:陈文宇
参考教材:?
评分标准:NaN
知识点总结
习题
Statistical Learning Theories and Applications (统计学习理论与应用)
写在前面
任课教师:文泉
参考教材:李航,统计学习方法(第2版),清华大学出版社,2019
评分标准:
1 Final Exam 50%: Open book test in two hours.
2 Projects 40%: Four projects (Regression, SVM, MLP, and Adaboost).
3 Presentation 10%: Presentation of new topics of machine learning by students).
知识点总结

Combinatorics (组合数学)
写在前面
任课教师:杨国武、卢光辉
参考教材:《组合数学及其应用》,清华大学出版社
知识点总结
符号表
符号
含义
N\mathbb{N}N
自然数集合
×\times×
直积
B\mathbf{B}B
重集
P(n,r)P(n,r)P(n,r)
从n个元素取出r个的线排列
C(n,r),(nr)C(n,r), \binom{n}{r}C(n,r),(rn)
从n个元素取出r个的组合数
F(n,r)F(n,r)F(n,r)
从n个元素取出r个的重复组合数
D(n)D(n)D(n)
n个元素的错排数
第一章-排列、组合与二项式定理
1.1 加法原理与乘法原理
Theorem 1.1.1 加法规则:设S\mathbf{S}S为有限集合,如果Si⊆S,S=⋃i=1mSiS_i \subseteq \mathbf{S}, \mathbf{S} = \bigcup_{i=1}^{m} S_iSi⊆S,S=⋃i=1mSi,且i≠ji \neq ji=j时,Si∩Sj=ΦS_i \cap S_j = \PhiSi∩Sj=Φ, 则有:
∣ ...
Tricks for DeepSNN Learning
写在前面
这是可以说的吗🫣🫣🫣
Efficient Training
调超参的时候可以先试试用Imagenet的100类试试,调的差不多了再上全部。
SNN Transformer Training
Transformer的常用Base lr是1e-4,adamw下是1e-4到6e-4之间,lamb可能需要再精调。adamw的前期收敛性太强了建议学习率linear warmup,用log怕炸
C-Optim
stdconv -> adaptive_clip clip_grad=0.02
正常的linear就torch自带的clip clip_grad=1 or 5
FasterViT?
Spike-driven Transformer V2/V3
检测与分割:除了backbone都是整数不norm
卷积算子貌似和整数(不带norm)很适配、attention貌似很和小数(带norm)适配
Spike-driven Transformer V1
About Finetuning SDT-V1 (Contributed by Qian S., 2025-04-28)
v1没有提 ...
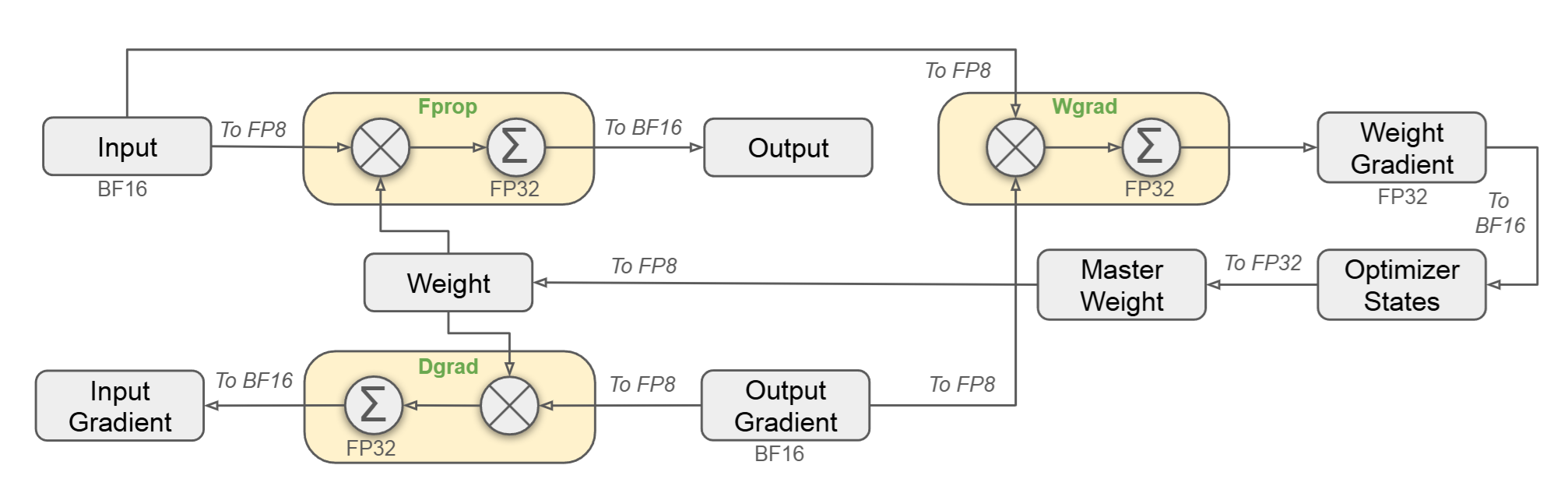
DeepGEMM-Beginner
写在前面
没错 这是一个新坑
为什么要做DeepGEMM的探索
某位师兄的MoE训练成本太高了,不得不借鉴Deepseek的FP8训练策略。于是我就来研究DeepGEMM了…
使用的算力平台
某超算中心(H20 Slrum)
环境配置
翻阅DeepGEMM的Github, 官方给出了所需的运行环境:
1234567Requirements- Hopper architecture GPUs, sm_90a must be supported- Python 3.8 or above- CUDA 12.3 or above- But we highly recommend 12.8 or above for the best performance- PyTorch 2.1 or above- CUTLASS 3.6 or above (could be cloned by Git submodule)
除了CUTLASS,其他的模块在超算中心中的modulelist中都能找到,这里我使用的配置是:
gcc_compiler10.3.0 cuda-12.4 cmake-3.24.0rc4 ...
My First Step in Bioinformatics
Refs
scPROTEIN(single-cell PROTeomics EmbeddINg): A Versatile Deep Graph Contrastive Learning Framework for Single-cell Proteomics Embedding [Github Link]
CLIP系列论文
Refs
Github Repo: jacobmarks:awesome-clip-papers
1. 经典中的经典:CLIP本尊
Title: Learning Transferable Visual Models From Natural Language Supervision
CLIP的核心工作是Contrastive Language–Image Pre-training,即对比语言-图像预训练,联合训练一个图像编码器和一个文本编码器来预测一批(图像,文本)训练样本的正确配对
123456789101112131415161718192021222324# image_encoder - ResNet or Vision Transformer# text_encoder - CBOW or Text Transformer# I[n, h, w, c] - minibatch of aligned images# T[n, l] - minibatch of aligned texts# W_i[d_i, d_e] - learned proj of i ...
Minkowski-Engine
Ref
Minkowski Engine Document
official code of “OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding”
定义与专业术语 Definitions and Terminology
下面介绍Minkowski Engine中的关于稀疏卷积的定义与专业术语。(基本都是汉化搬运Ref.1,力图加上我的一点个人理解)
稀疏张量 Sparse Tensor
首先引入稀疏矩阵:是一个零元素占整个矩阵元素的绝大多数的矩阵。而稀疏张量是稀疏矩阵的维度扩展,其中非零元素用索引 Indices(记为C\mathcal{C}C)和与其对应的值 Values/Features(记为F\mathcal{F}F)。
Indices作为稀疏张量非零元素的位置表示,Values则是这个元素本身的值。
在实际应用中,我们用**坐标列表 COOrdinate list (COO)**的格式对稀疏张量进行存储。这种存储策略本质上是将稀疏张量中的非零元素坐标拼接(co ...
FilterNet
Ref
{ % FilterNet_2411.01623v2.pdf % }
Motivation
解决的问题:神经网络对于时序预测的不准确性(Timeseries forecasting)
点名批评 iTransformer
主要贡献:
在研究基于深度Transformer的时间序列预测模型时,通过一个简单的模拟实验,研究者们观察到了一个有趣的现象,这激发了他们探索一种新的角度,即将信号处理技术应用于深度时间序列预测。
受到信号处理中滤波过程的启发,研究者们提出了一个简单而有效的网络——FilterNet。这个网络基于两个可学习的频率滤波器构建,这些滤波器能够通过选择性地通过或衰减时间序列信号的某些成分来提取关键的信息性时间模式,从而提高预测性能。
研究者们在八个时间序列预测基准数据集上进行了广泛的实验。实验结果表明,与现有的最先进的预测算法相比,他们的模型在有效性和效率方面都取得了更优越的性能。
Methods
网络架构
输入的时间序列数据(LLL为观测时间窗长度,NNN为变量个数),表示为
X=[X11:L,X21:L,…,XN1:L]\bf X=[{X}_{1 ...