![毕业设计(二)文献阅读 [ICML 2022] Monarch:Expressive Structured Matrices for Efficient and Accurate Training](https://s2.loli.net/2024/07/29/z8fJRjlQDnZsxVC.png)

EMS-YOLO的魔改记录
EMS-YOLO的工程结构
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758EMS-YOLO├─ .ipynb_checkpoints├─ LICENSE├─ README.md├─ __pycache__├─ data├─ detect.py├─ environment.yml├─ export.py├─ firerate10_5.npy├─ g1-resnet├─ hubconf.py├─ models # 网络模型文件│ ├─ __init__.py│ ├─ common.py│ ├─ common_origin.py│ ├─ experimental.py│ ├─ res10-ee.yaml│ ├─ res18-ee.yaml│ ├─ res18-eebk.yaml│ ├─ res18-sew.yaml│ ├─ resnet10.yaml│ ├─ resnet18.y ...
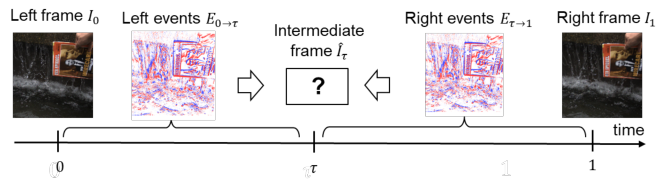
Event-based VFI
Reference
[1] H. Cho, T. Kim, Y. Jeong, and K.-J. Yoon, “TTA-EVF: Test-Time Adaptation for Event-based Video Frame Interpolation via Reliable Pixel and Sample Estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 25701–25711.
[2] J. Dong, K. Ota, and M. Dong, “Video Frame Interpolation: A Comprehensive Survey,” ACM Trans. Multimedia Comput. Commun. Appl., vol. 19, no. 2s, May 2023, doi: 10.1145/3556544.
[3] O. S. Kılıç, A. Akman, a ...
![毕业设计(一)文献阅读 [NeurIPS 2020] Neural Sparse Representation for Image Restoration](https://cdn.jsdelivr.net/gh/EricZhang1412/PicGoStorage@master/img/20240725153218.png)
毕业设计(一)文献阅读 [NeurIPS 2020] Neural Sparse Representation for Image Restoration
参考文献
(带标注,仅供参考)
方法
1. Hidden neuron的稀疏化
一个通用的表示图像恢复任务的神经网络表示为如下: (为什么如此建模作者在Related Works中有描述)
Y=W2∗F(W1∗X)\mathbf{Y} = \mathbf{W_2} * \mathcal{F}(\mathbf{W_1} * \mathbf{X})
Y=W2∗F(W1∗X)
Notes
Description
Connections w.r.t image restoration tasks
X\mathbf{X}X
输入图片
以图像超分为例,代表输入的低分辨率图片
Y\mathbf{Y}Y
输出图片
以图像超分为例,代表输出的高分辨率图片
F(⋅)\mathcal{F}(\cdot)F(⋅)
神经网络中的非线性激活函数
一种稀疏表示的方式,但文章中认为不是很高效
W1\mathbf{W_1}W1
卷积核1
线性投射到高维空间的基矩阵(或者说是投射的token,作为基底来表示用token线性组合,即图片本身)
W2\mathb ...

FPGA_System_Design
00. 学习在PL端使用OV7725摄像头
拿到摄像头,我们先来研究它的引脚:
输入端口:
Port
Function
XCLK
系统时钟输入
FSIN
帧同步信号输入
RSTB
系统reset信号输入,低电平有效
PWDN
关机模式选择
SCL
SCCB协议时钟输入(类似IIC)
SDA
SCCB协议数据输入(类似IIC)
输出端口:
Port
Function
HREF
行同步信号输出
PCLK
像素时钟输出
VSYNC
垂直同步信号输出
D[9:0]
10-bit RGB数据
Step 1. 读出OV7725的RGB数据并拼成一帧图像
假设摄像头正常工作,自身产生的24MHz的PCLK作为输出给到读取数据的模块中。一系列像素同步信号(VSYNC,HREF)和本身的RGB像素信息也同样传给模块中。作为时序控制电路应有RST_n信号。所以该Verilog模块的输入输出端口就很清晰了(如下图)
Ports
Port name
Direction
Type
sys_rst_n
input
wire
...

VIT_Need_Regs_ICLR_2024
如何生成有一定可解释性的Attention Map
参考Github Repo: jeonsworld/ViT-pytorch
我们先试着跑一跑仓库里的train.py,本人写了一个脚本方便快速运行,作者也提供了预训练权重(.npz)。这里以ViT-B-16的模型为例:
12345678910111213141516171819202122python train.py \ --dataset cifar10 \ --model_type ViT-B_16 \ --pretrained_dir "checkpoint/imagenet21k+imagenet2012_ViT-B_16.npz" \ --output_dir "./outputs" \ --img_size 224 \ --train_batch_size 256 \ --eval_batch_size 4 \ --name "exp_1" \ --eval_every 100 \ --learning ...

FireFly-v1-FPGA Simulation
参考文献
FireFly: A High-Throughput Hardware Accelerator for Spiking Neural Networks With Efficient DSP and Memory Optimization, IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 10.1109/TVLSI.2023.3279349
URL: https://ieeexplore.ieee.org/document/10143752/
其他参考资料
UltraScale Architecture DSP Slice, UG579 (v1.7) June 4, 2018
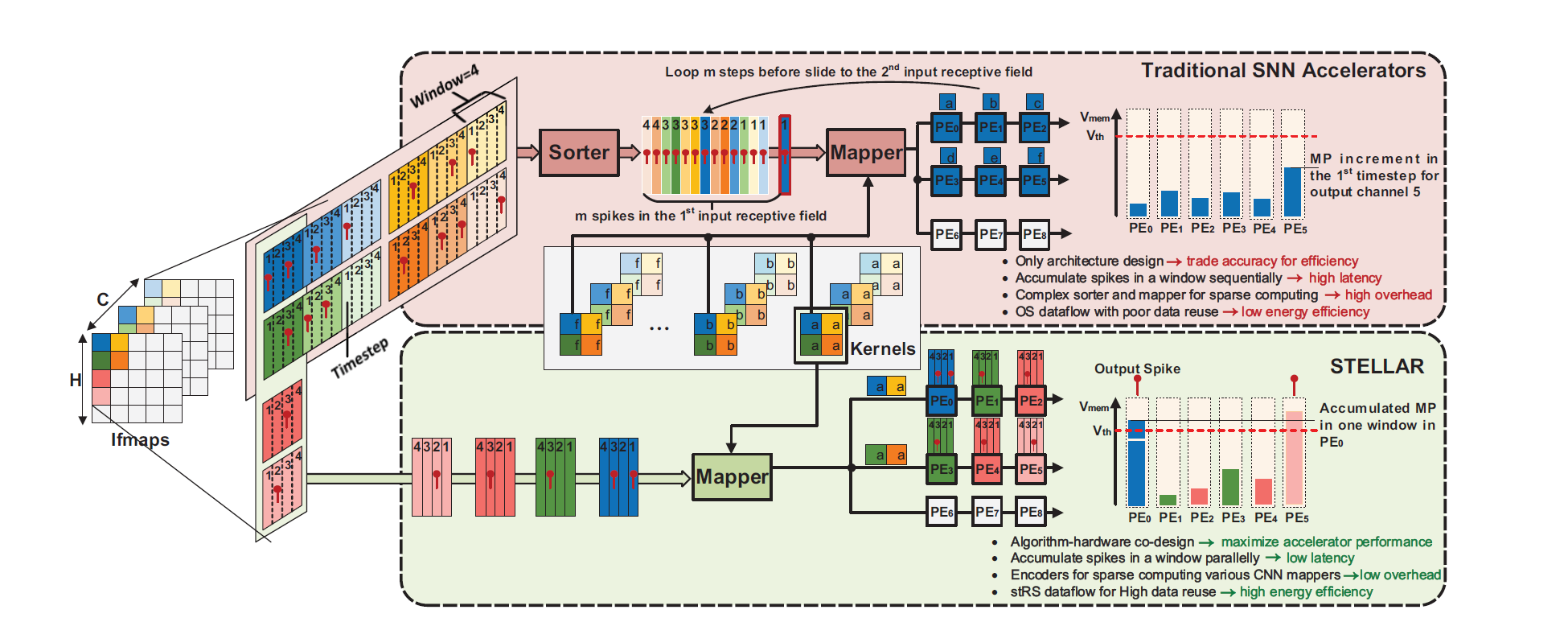
1. 通过单个 DSP48E2 进行突触交叉计算 (Synaptic Crossbar Computation by a Single DSP48E2)
DSP48E2是Xilinx Ultrascale SoC中会提供的一个数字信号运算IP,基本架构在下两图所示,由三部分组成:
27位预加器 (27’b p ...
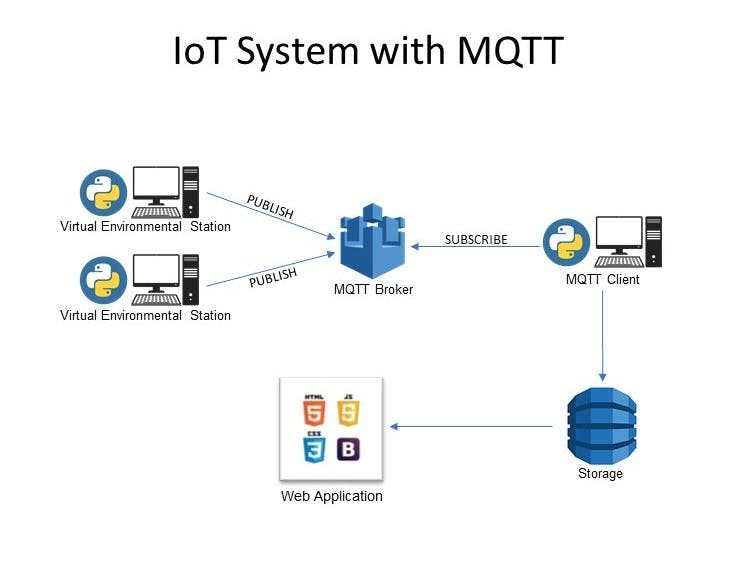
ARM-Linux-MQTT移植
在ZYNQ 7020 PS端使用paho.mqtt实现设备侧开发连接华为云IoTDA服务
(2024-2025第六学期综合课程设计自主设计任务的一环)
参考资料
https://blog.csdn.net/thisway_diy/article/details/125557534, 【嵌入式Linux应用】初步移植MQTT到Ubuntu和Linux开发板, 韦东山
https://www.cnblogs.com/wanqieddy/archive/2011/09/21/2184257.html, Makefile 中:= ?= += =的区别, wanqi
https://support.huaweicloud.com/devg-iothub/iot_02_2200.html, MQTT使用指导, 华为云
0. Ubuntu18.04 WSL准备
教程很多有手就行。
1. 前置包准备
Paho MQTT的包对多种语言都有支持,其中特别是嵌入式设备中(之前bz用过海斯Hi3861的paho-embedded-mqtt,是工程师事先构建好在OpenHarmony镜像中,用户 ...

2023_NUEDC
2023 NUEDC Question C
(项目链接在报告里有写的喵) <----(你喵个锤锤子)